
I have been experimenting a lot lately with agentic systems. Like many folks I am using agentic tools to do software development, operations, and other technical tasks. For most, using Claude Code, Codex, etc. gives them enough for long horizon tasks and I agree for most use cases.
But, as an AI tinkerer I have been experimenting by wrapping the “harness” to create longer running agentic workflows. My first foray into this was with a Ralph loop. A few months ago wrapping the harness in a loop was the only way I could get long horizon (multi-hour) tasks to succeed. I used this technique to successfully convert tools across languages, troubleshoot challenging container build scenarios, and continue the exponential of token usage. I definitely also had some failed runs, and wasteful loops that just got stuck running tests, and going back and forth on the same fix. Since then Claude Code and Codex have both improved their task management and long horizon workflows and I rarely use Ralph loops as I am able to get multi-hour sessions natively in the harness.
Of course, that didn’t stop me from continuing my tinkering, and my other area of interest for agents is (re)search. Search is the fuel for generating good context, so solving search for your agent is often the difference between success and failure at a given task. I spent the last several years working on search relevance systems and I have already built more than my fair share of RAG demos and while they can elicit a pretty visceral response the first time you see a model gather business logic from your data source, telling the model what context it needs seemed dated in 2026.
In Steve Yegge’s Vibe Coding book, there is a passing paragraph from Boris Cherny (creator of Claude Code) about how they originally started with a vector search RAG approach but have since moved onto giving Claude access to grep and letting the model search for itself. This was not a new revelation to me, but seeing it in print and having just built a Ralph loop I wanted to apply this to a thorny search problem to see what I could do.
One of my favorite search problems to think about is Reddit. Reddit is a gnarly search problem. Huge corpus, natively unstructured, and famously bad internal search. I wondered if I could dent it. Here’s how I approached building an agentic search tool, called hiveminer.
Start with a CLI (always)
With vibecheck I learned to start with a CLI tool as a way to not just rapidly prototype, but rapidly build with agents. I have long subscribed to CLI first already as similar to mobile it forces you to think critically about what is really needed and what the core workflows for your API are. In this case it was simple. My agent just needed a basic way to search Reddit.
I started with a simple Google search and nothing obvious popped up that met my requirements but with clean APIs, and a few prompts I was up and running with a Go based Reddit search interface. Very quickly I was in Claude asking it to find me the “best android phone”, “best family vacation” but not surprisingly searching all of Reddit for “best android phone” didn’t really work well. Having Claude reason about the results and recommend the best subreddits to search validated the agentic side would be effective but Reddit is huge. I needed a way to do more in depth research.
Problem Space
I took a step back and thought about the problem. The problem as I saw it was searching for “best android phone” was subjective and personal. A sales person would ask about your use case, maybe what specs matter to you, price range, etc. All details that undoubtedly exist in the underlying Reddit threads but weren’t being used to evaluate the quality of results.
So refining, the problem I needed users to provide a structured set of questions they want answered not just a simple search. This is what you do when you try to research something on Reddit. I also needed that process to be easy to assemble, but quantitatively verifiable so that if a user says they want phones < $999 the results score that appropriately.
Stepping back further this abstractly is generating structured data from raw unstructured content. A nice weekend challenge 😎
Conceptual Abstractions
With a solid foundation for the problem space, I went about further designing the solution. It’s probably obvious at this point that I am not new to building agents and I had some key concepts that I wanted to leverage. I am not going to go into all of them here (more posts to come) but I do want to cover the ideas of cascading retrieval and an extraction schema which are required concepts for understanding how hiveminer works.
Let’s start with the extraction schema concept. This is just a fancy way of rephrasing what I covered in my previous problem statement. Searches need to rigorously define their success criteria. To do this I created a JSON DSL for defining the form (something Claude has tons of pretraining data on so this was easy to whip up). To make the process intuitive and guide users to ask specific questions I created a skill that uses the Ask User Question tool natively in Claude.
The second concept is a search concept known as cascading retrieval. In a Reddit sense this can be thought of simply as what subreddits should I search? You may know this a priori for specific searches and then you probably don’t need hiveminer, but if you’re doing broad market research or something more diffuse then there may not be a single obvious candidate. Cascading retrieval first elects the best candidates to search, then searches the best candidates.
Building a pipeline and state management
At this point I had the raw pieces, but I still needed to bring it all together. This was just a classic flow control problem at this point and I needed to define execution phases. As I just covered the first phase would be a discovery phase (which subreddits to search). Then I needed to parse the extraction schema, and use that to discover and evaluate the best threads (I could do this in parallel). Finally I needed a step to rank the results (classic search architecture).
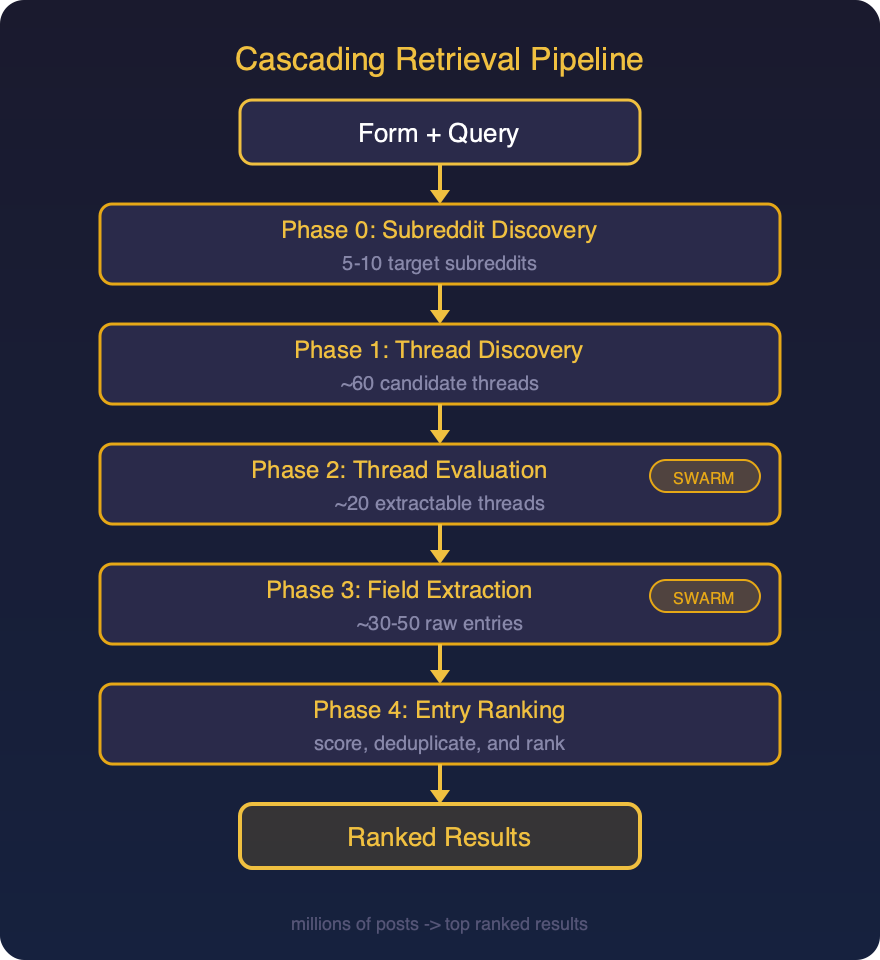
Doing all of this meant keeping track of state, which I briefly experimented using beads for but decided to just use the file system in the end. There was a lot more to implementing these steps and in the process I ended up spinning off my own Go SDK for building agents called belaykit that I’ll cover in more detail in a future post. Suffice it to say a lot of interesting engineering went into these steps as it relates to state management, observability, interrupt handling and other common concerns for CLI based agents.
Bringing it all together in some examples
I needed examples of searches I could use and assess results. This has turned out to not be easy to baseline and I’d love community submissions here but I landed on a few I felt I could reasonably assess just based on my own taste. The two I mentioned previously, and then a more specialized vacation planning one for a Christmas markets trip I am planning with the family. Of course the reality is that I can’t actually know for sure the results are the best but I can assess if the results are helpful on these specific queries.
And they are! Check out the results for the best Christmas markets with skiing below.
Try it out and next steps
Hiveminer is completely free to use with your Claude subscription. Try it out. Next up I plan to blog about belaykit and best practices for developing your own specialized agents in Go!
